How to Get Started With Big Data: Hadoop & Hortonworks (Cloudera)
I’ve been working with Big Data for a couple of years, and haven’t written much about it so far. Until recently the bulk of my work has been using Hortonworks (now merged with Cloudera).
In this post, I cover getting started with the HDP Virtual Machine and starting hive, in preparation for future posts on Hive and Big Data.
The notes I’ve drafted (so far) have revolved around Hive (and Hive Query Language/HQL) for ETL and analytics work. Although I’ve made use of many other aspects of the platform in this time.
Note: I’m writing this based on working with the HDP (Hortonworks Data Platform). Cloudera have their own CDP (Cloudera Data Platform). Both have their differences, but with the companies merging there will probably be a combining of platforms.
What Is Big Data
Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.
– The Internet
Big data, like the term “cloud” is open to interpretation and muddied by marketing departments of companies selling software and solutions. For me it’s characterised by data volumes that our traditional RDBMS platforms can’t really cope with, and requires “big data” technologies to work with it (I’m aware this is a circular definition).
What Is Hadoop & Cloudera
Apache Hadoop is a collection of open-source software utilities that facilitate using a network of many computers to solve problems involving massive amounts of data and computation. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model.
Wikipedia
Cloudera, Inc. is a US-based software company that provides a software platform for data engineering, data warehousing, machine learning and analytics that runs in the cloud or on premises.
Wikipedia
I think of Hadoop as being like Linux, there is an open source core which sits at the heart of it. Cloudera is like Ubuntu, mixing the open source bits together in a particular blend and distributing it in various forms and selling support, services and extra software on the top.
Getting Started with the VM
Some big data solutions such as AWS require you as a user to sign up to their service and use their cloud provision (with a generous amount of free starting credit). What I like about Cloudera (Hortonworks) is the “on premises” offerings. If you are prepared to look after the hardware and everything, why not try it out.
Hortonworks/Cloudera offer a handy little VM which has all the software installed and configured (not everyone has the time and inclination be be a Linux sys admin just to get playing with a data solution). Which is what I’m using to play with and create any samples/demos used here.
I chose to use the VirtualBox image so I could easily move it between hosts, and access it over my LAN.
- Chose a VM host:
- VirtualBox
- VM Ware
- Docker
- Download the Hortonworks HDP Sandbox (this can take some time), matching your choice of VM Host.
- Bookmark the documentation: Learning the Ropes of the HDP Sandbox
- Bookmark the documentation: Getting Started with HDP Sandbox
Setting up the VM
It should be easy to download and setup the VM. If you get lost in the initial step, there is a short video from Hortonworks.
I am running the VM on a different host machine (my home laptop ) which required me changing the network configuration to enable port forwarding. Simply remove 127.0.0.1 from the “Host IP” column (leaving it blank) for each port you’d like to access over the network (such as AmbariShell 4200, ambari 8080, DAS 30800 and Tutorials 1080).
Initial Configuration of VM
It’s worth reading and stepping through the Hortonworks Documentation of Learning the Ropes of the HDP Sandbox at this point.
The first things you will need to do are:
- Map Sandbox IP to Your Desired Hostname in the Hosts File (if like me you want to access the sandbox from another machine on your LAN, then this has to be done on the machine you will actually be using rather than the VM host).
- Reset the admin password (and root password).
Next Steps
As HDP & The virtual Machine technology comprises of many areas, what interests each person is going to be different. Most of my notes that I’ve got drafted for future posts revolve around Hive (SQL Style language for ETL and data access).
Hive (Data Analytics Studio)
To start with a hive query, go to Ambari (this is on port 8080). On the menu down the left, click on “Data Analytics Studio”. Then click on the link to the right “Data Analytics Studio UI” (which is on port 30800).
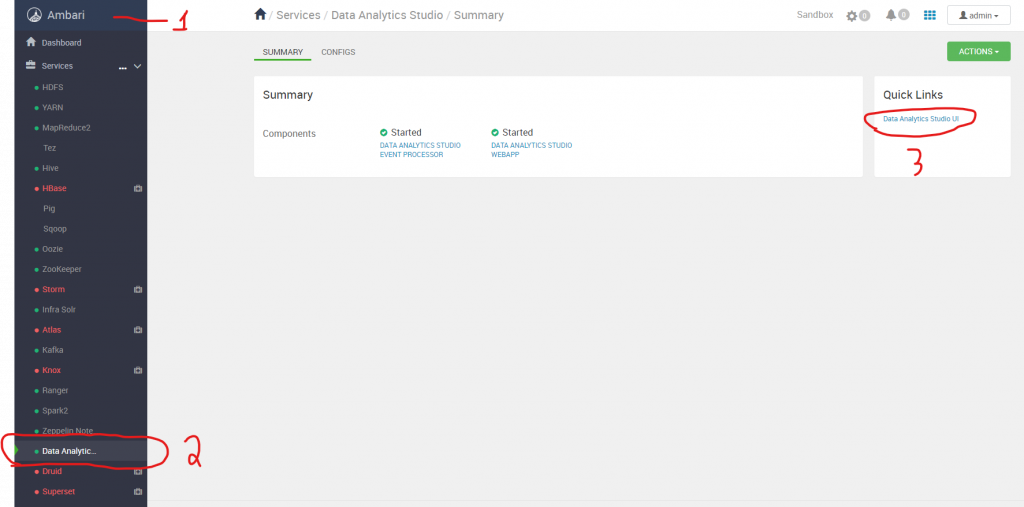
Note: you will need to have configured the hostname: Map Sandbox IP to Your Desired Hostname in the Hosts File.
You can now use hive (and Hive QL) similar to using SQL in a traditional RDBMS (note some actions will seem strangely slow in this environment). Some commands to get started with are:
SHOW DATABASES;
CREATE DATABASE testing_ground;
USE testing_ground;
CREATE
TABLE testing_table_1
(
id_col BIGINT,
val_col VARCHAR(100)
);
SHOW TABLES;
DESCRIBE testing_table_1;
INSERT
INTO testing_table_1
(id_col,val_col)
VALUES(1 , 'Desc')
;
SELECT *
FROM testing_table_1
;
Everything Else
For everything else, see the documentation:
- Getting the VM up and running: Learning the Ropes of the HDP Sandbox
- Understanding the components & tools available: Getting Started with HDP Sandbox
One Reply to “How to Get Started With Big Data: Hadoop & Hortonworks (Cloudera)”